Dies ist ein Beispiel der Zeitreihenanalyse mit dem PrediFo Paket. Zu Beginn der Analyse und des Forecastings steht die deskriptive Statistik, um einen Gesamteindruck der Daten zu bekommen.
Die Zahlen sind reale neutralisierte Umsatzzahlen, die hier aus einer Azure SQL-Datenbank eingelesen werden.
Wichtig ist hier auch die Interpration der Daten und nicht nur eine Präsentation der Grafiken.
Deskriptive Statistik
Interpretation:
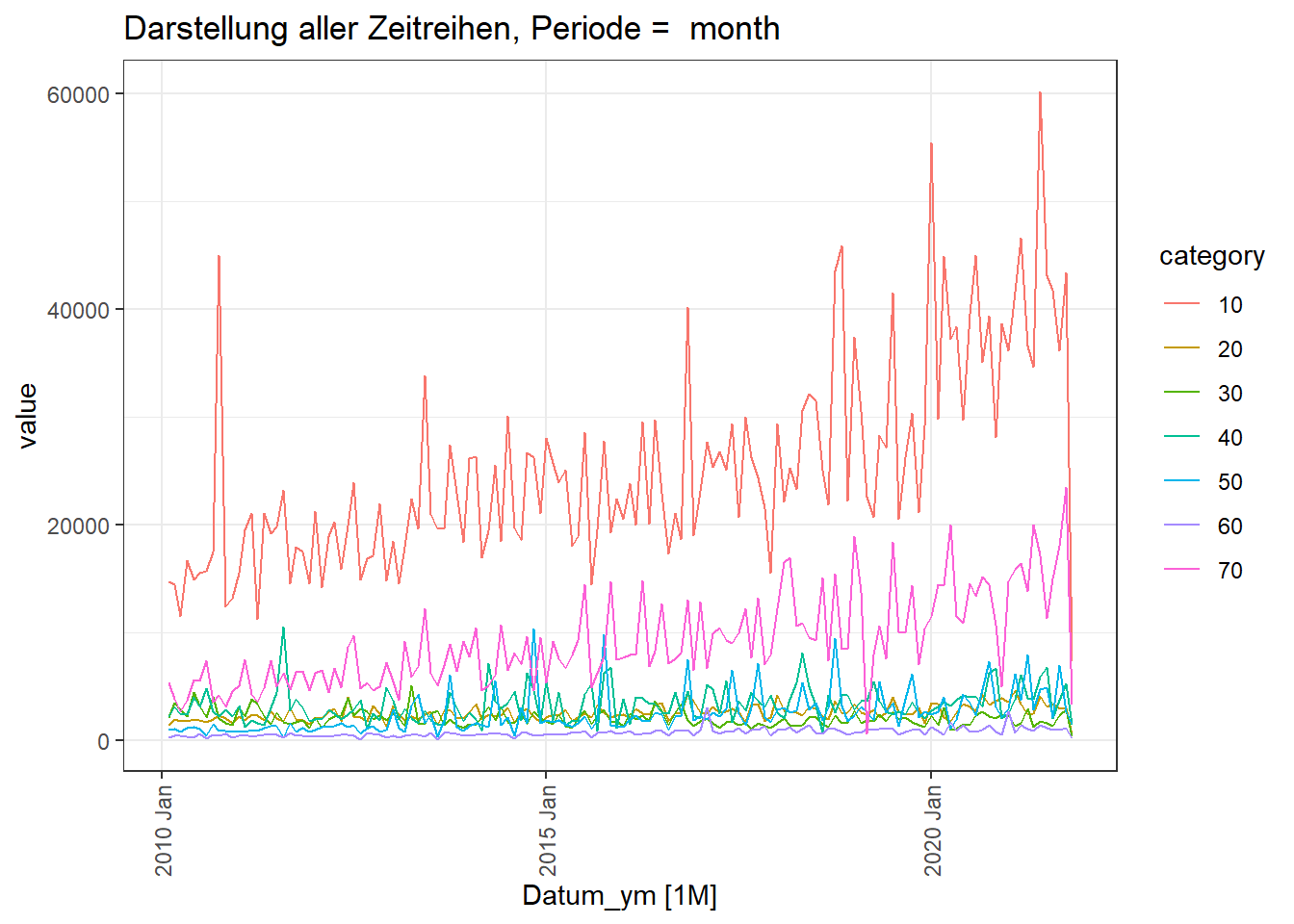
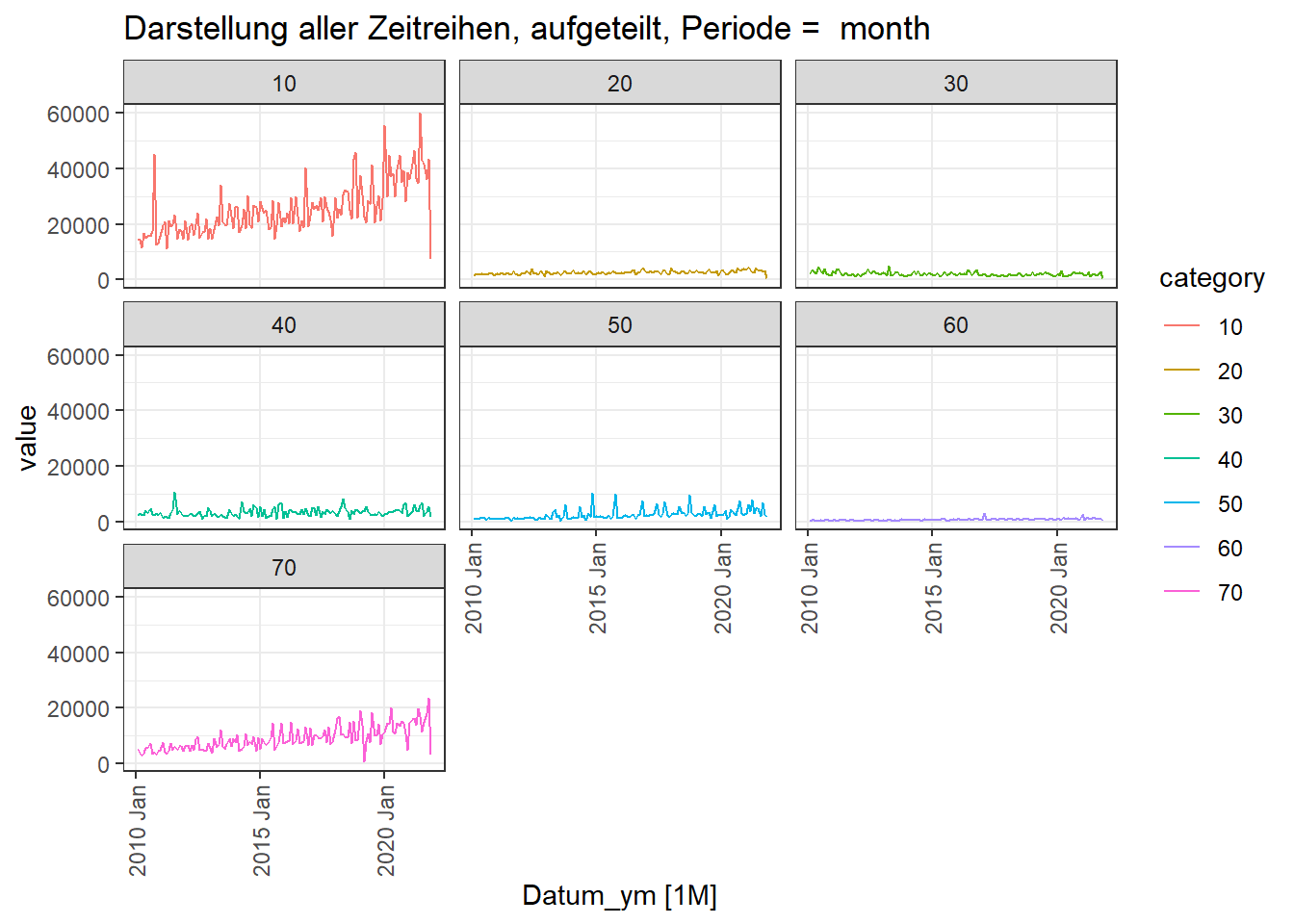
Kategorie 10 hat deutlich höhere Werte
Alle Kategorien zeigen eine hohe Streuung.
Das Absinken der Werte am Ende liegt an der nicht kompletten Periode beim abspeichern der Daten. Dies muss z.B. beim Forecast berücksichtigt werden.
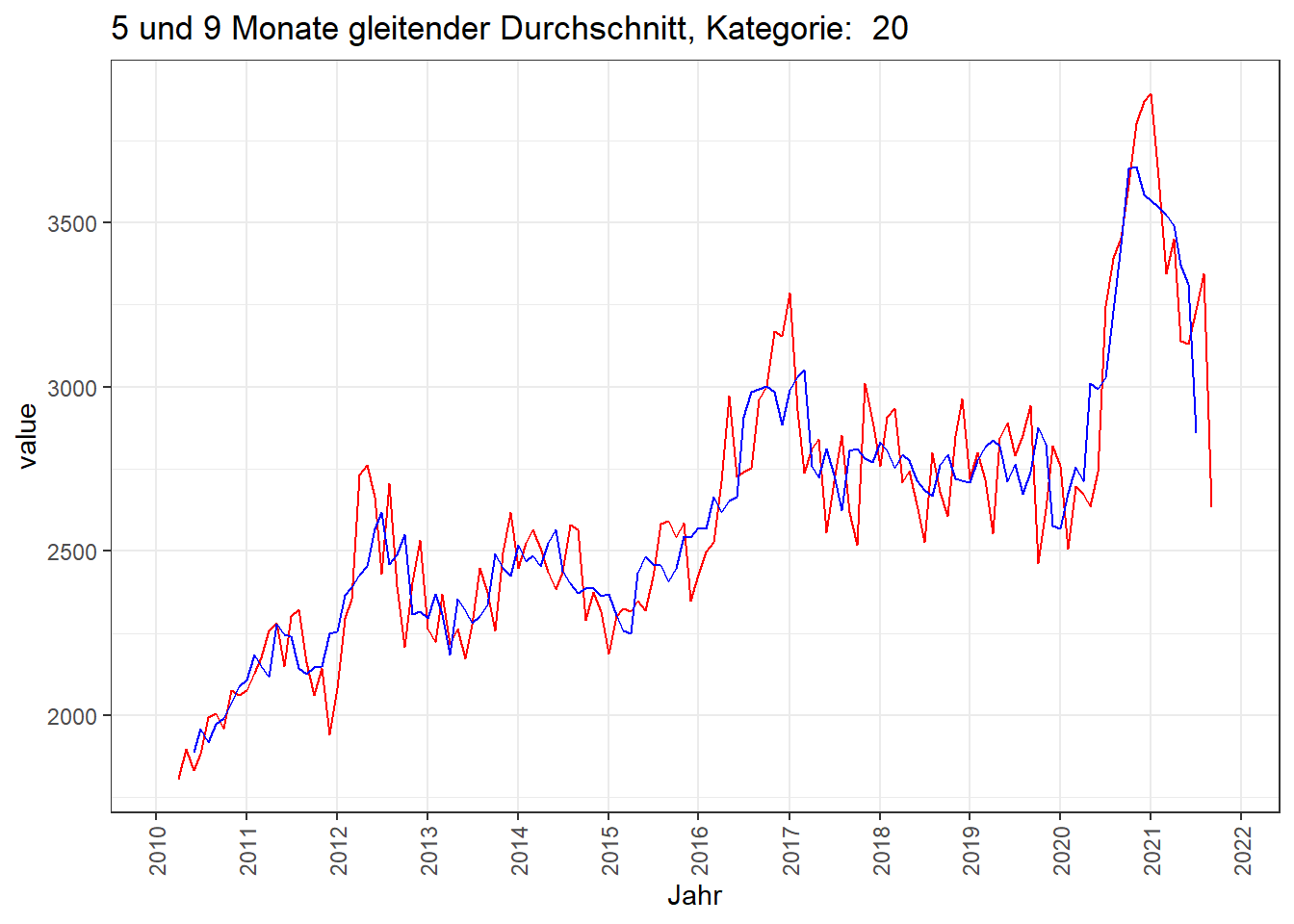
Gleitender Durchschnitt
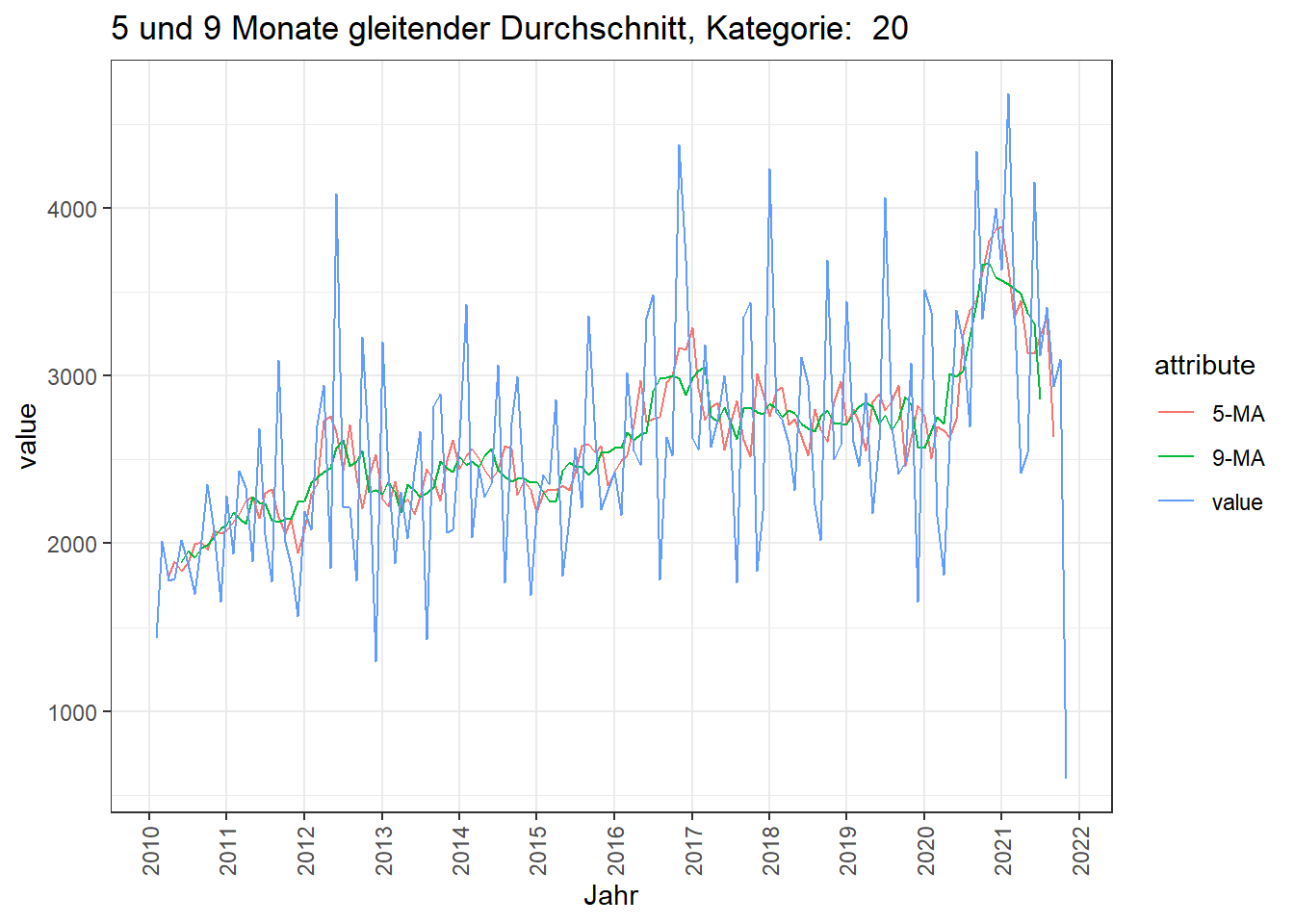
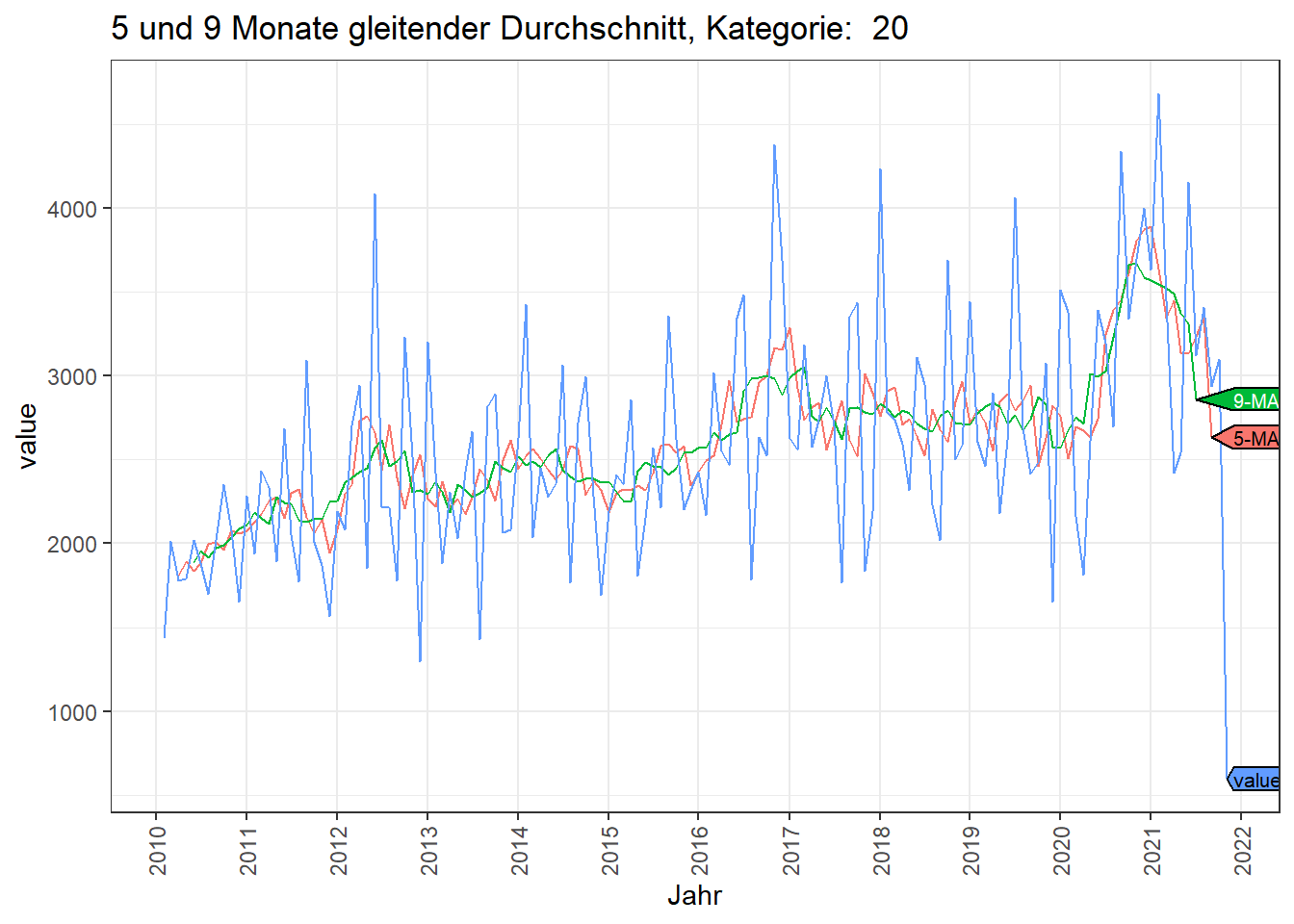
Hier wird ein gleitender Durchschnitt berechnet, wobei der jeweilige Wert der Mittelwert aus den Werten vor und nach dem jeweiligen Einzelwert ist. Somit können Gewichtungen realisiert werden.
Im Beispiel wird ein 5 Monate und 9 Monate moving average (MA) dargestellt.
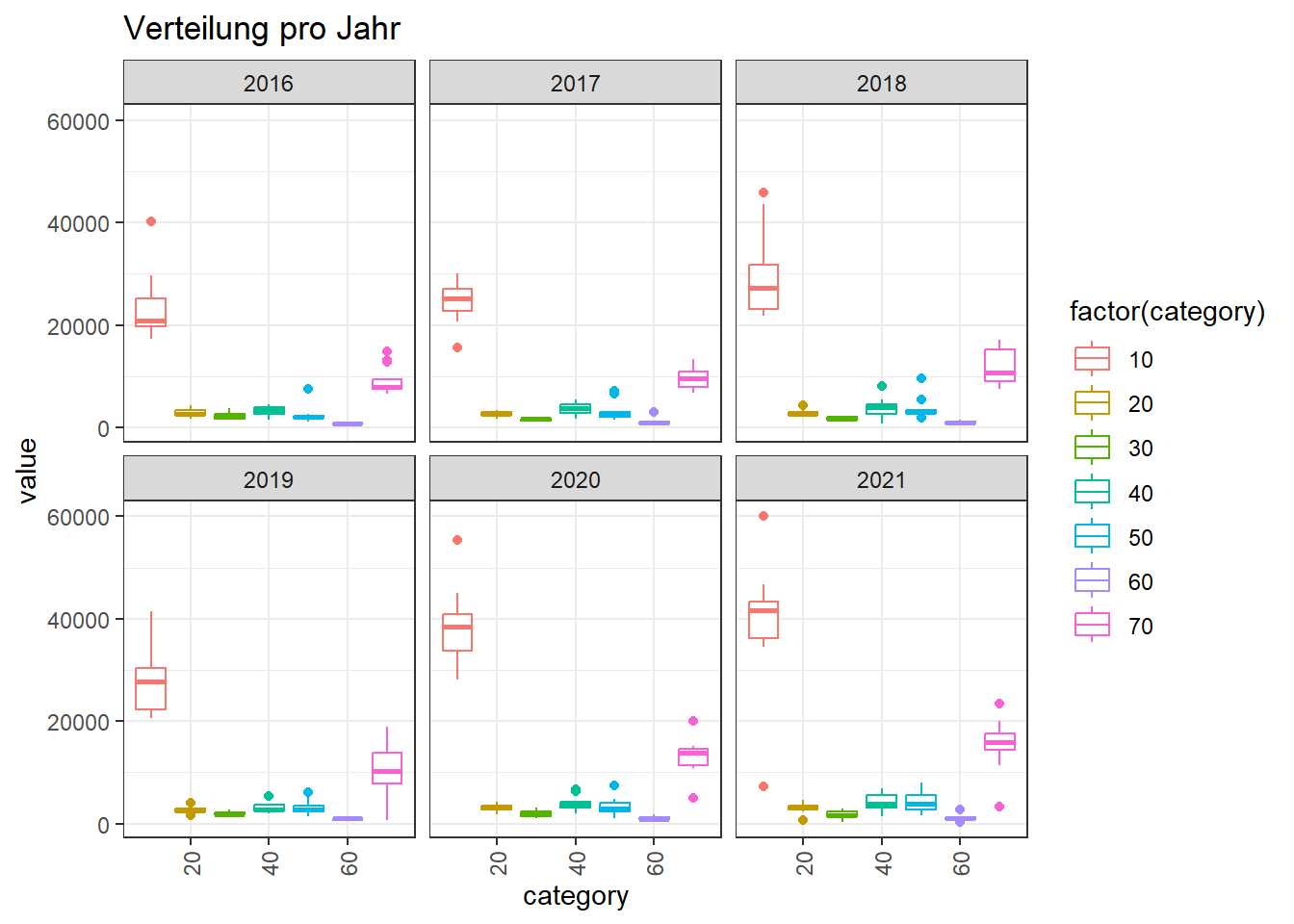
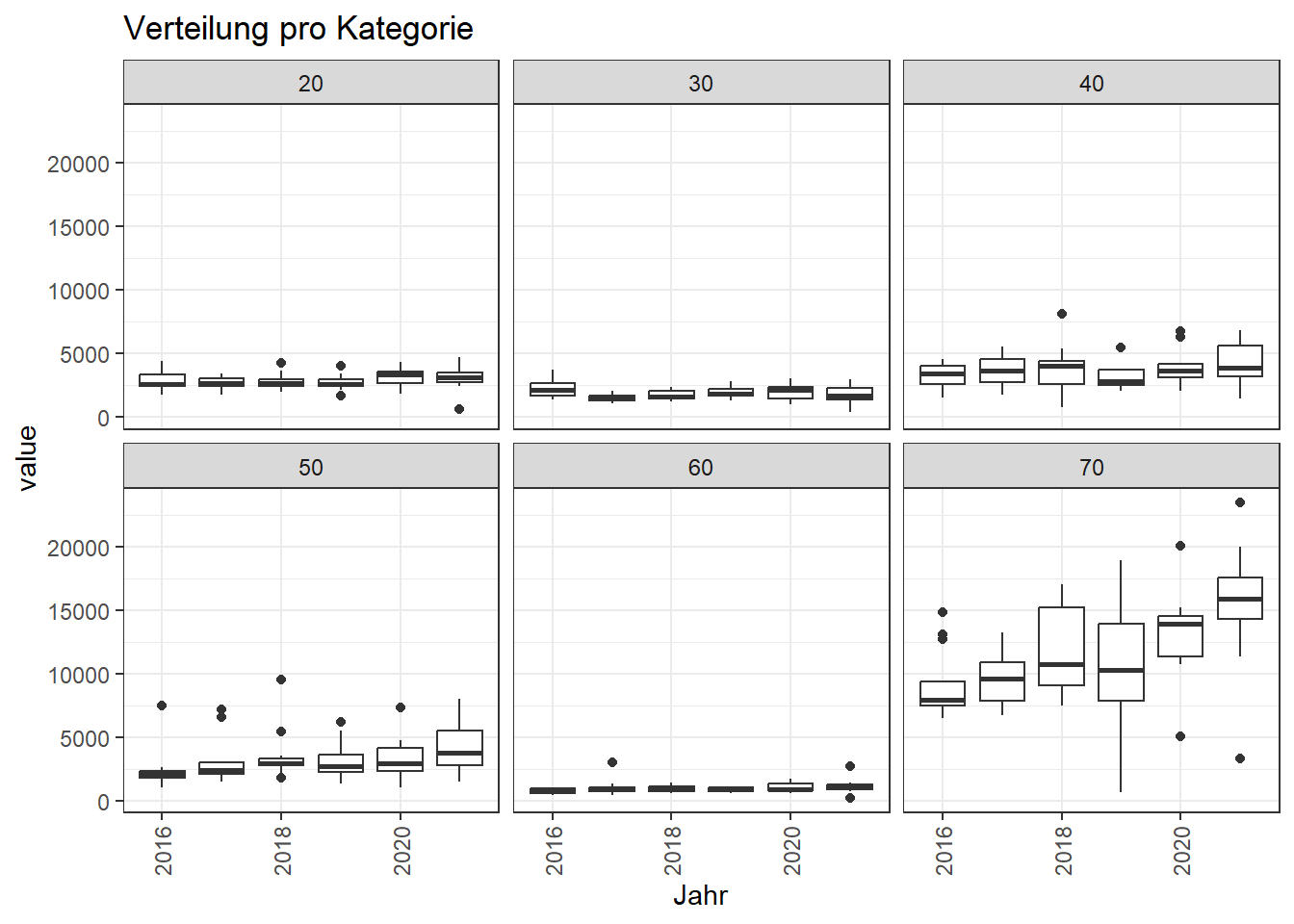
Verteilung und Ausreißer
Mittels Boxplots können die Verteilung und Ausreißer erkannt werden. Für die Prognoseberechnung können die Ausreißer dann eliminiert werden.
Interpretation:
- Speziell Kategorie 10 und 70 zeigen eine hohe Bandbreite der Werte.
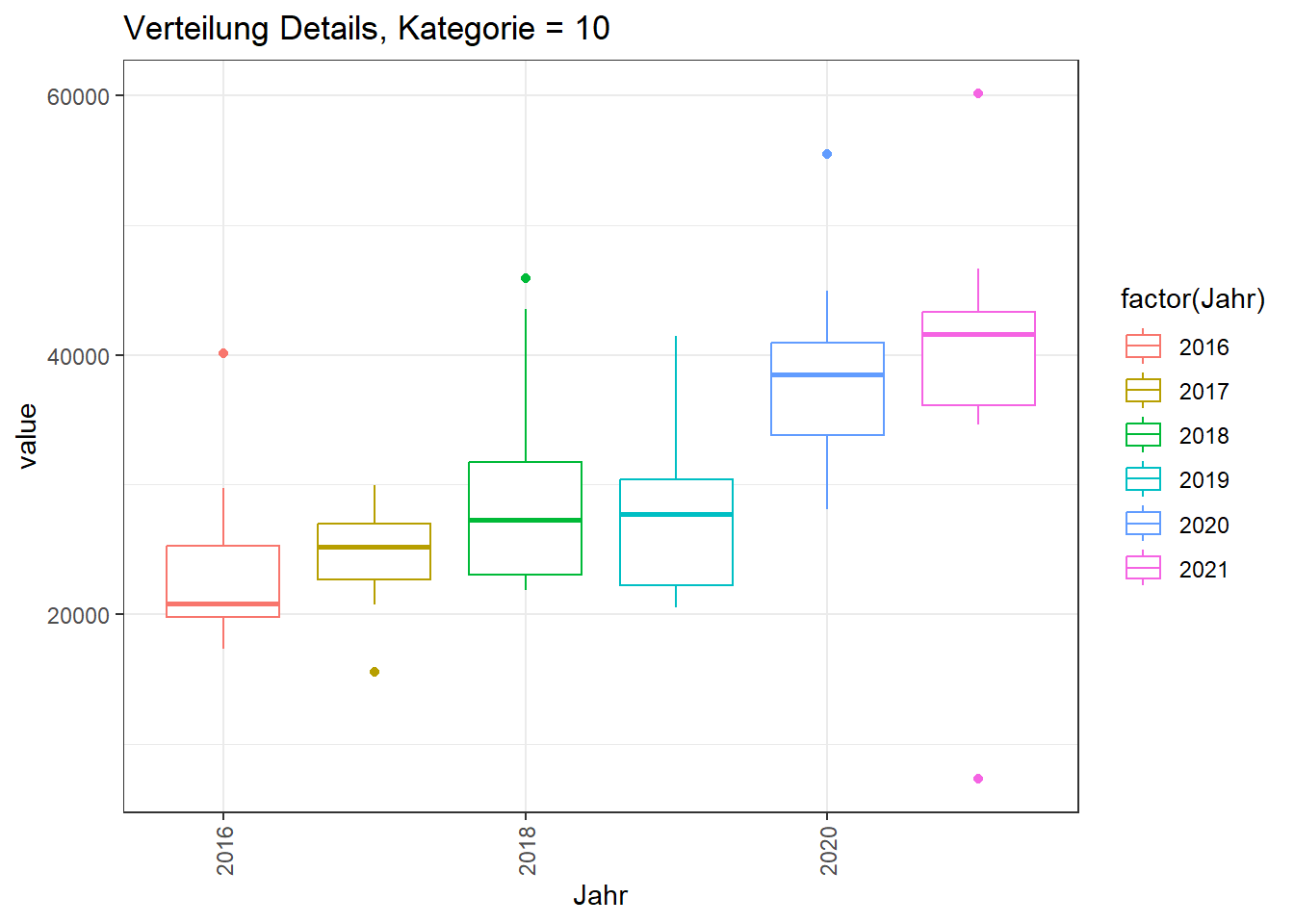
Details
Klassische statistische Werte können relativ leicht aufgelistet werden.
| für 2026 und 2027 pro Kategorie |
| min |
max |
median |
mean |
Summe |
| 2016 |
| 10 |
17349 |
40135 |
20821 |
23587 |
283039 |
12 |
6544 |
| 20 |
1783 |
4378 |
2593 |
2872 |
34470 |
12 |
731 |
| 30 |
1410 |
3702 |
2150 |
2287 |
27444 |
12 |
765 |
| 40 |
1563 |
4591 |
3411 |
3291 |
39489 |
12 |
946 |
| 50 |
1057 |
7487 |
2122 |
2439 |
29264 |
12 |
1656 |
| 60 |
440 |
1008 |
834 |
782 |
9390 |
12 |
207 |
| 70 |
6505 |
14804 |
7954 |
9076 |
108913 |
12 |
2774 |
| 2017 |
| 10 |
15588 |
29993 |
25235 |
24658 |
295891 |
12 |
4018 |
| 20 |
1765 |
3437 |
2665 |
2664 |
31974 |
12 |
538 |
| 30 |
1107 |
2097 |
1630 |
1556 |
18674 |
12 |
289 |
| 40 |
1753 |
5536 |
3685 |
3647 |
43764 |
12 |
1218 |
| 50 |
1495 |
7206 |
2413 |
3082 |
36978 |
12 |
1838 |
| 60 |
479 |
3031 |
969 |
1084 |
13007 |
12 |
661 |
| 70 |
6705 |
13265 |
9646 |
9725 |
116704 |
12 |
2211 |
Export
Alle aufbereiteten Daten können exportiert werden. Aktuelle Möglichkeiten:
Azure SQL Datenbank
SQL Datenbank
CSV Datei
Excel Datei